Since our talk, every few months, I’ve gotten the urge to write a blogpost about the paper. Among other cool things described in the paper, we…
- Implemented a powerful machine-learning-assisted side-channel attack that can be pulled off in any modern web browser
- Demonstrated for the first time in the literature that system interrupts, a low-level mechanism that your operating system uses to interact with hardware devices, can leak information about user activity
- Learned a valuable lesson about the dangers of applying machine learning toward hardware security research
I think some of these lessons are widely applicable, even outside of hardware security research. But each time I’ve started writing, a few hundred words into the draft, I’ve stopped writing and put the post away. For some reason, it always felt wrong. Two years later, no blogpost exists. If I could write about other people’s research, why couldn’t I write about my own? I only recently figured out why.
As I’ll get into, one reason this is a hard post to write is because there’s a lot going on in this research paper. I like writing for a general technical audience, and I need to explain a lot of background before I can get to the good stuff. The paper also has two competing stories: one about how machine learning models can be used to attack web browsers, and another about how these same models are often misunderstood, leading them to be applied incorrectly. But there’s also a third story embedded in this paper, about how this paper completely altered the trajectory of my life. This is a post about machine learning, computer architecture, and more, but also about myself, how I got into research and academia, and how one great mentor can change everything.
Select your CPU
This post contains demos and details that can be customized to your CPU. If you know your processor, you may search for it below:
Otherwise, feel free to pick a sample CPU from the list below:
It was September 2020, the start of my junior year at MIT, and I had just enrolled in Secure Hardware Design, a graduate seminar class that was being offered for the first time. Nearly all of my past experience had been in software, and I saw the class as a great opportunity to branch out and learn new things.
I quickly found out I was in over my head. Each week, we would read and discuss two recent hardware security research papers as a class. Of the 10 or so students who came each week, I was one of only two undergrads, and half of the PhD students weren’t even enrolled in the class—they just wanted to discuss the papers for fun. I felt that I had very little to contribute to the discussions compared to the wealth of experience everyone else brought to the table, but I was happy to listen nonetheless.
Alongside the paper discussions, each student was supposed to complete a final project. I met with our professor, Mengjia Yan, early on in the semester to discuss where I should start. I told her about my prior experience with web development and machine learning, and she suggested I try to reimplement a recently published website fingerprinting attack, which relies on machine learning to exploit weaknesses in hardware. Her gut told her that there was something wrong with the state-of-the-art research in that area, but she couldn’t put her finger on what it was.
A primer on side-channel attacks
In a perfect world, applications on your computer should always operate independently of each other. For example, if you have Netflix and Spotify open at the same time, Spotify should never be able to know what movie you’re watching. In practice, this is mostly kept true because of a mechanism known as process isolation, through which your operating system keeps applications separate from each other by making them use separate resources. For example, applications are given their own private memory space to store their data, and are restricted from accessing memory that belongs to another process.

However, process isolation is highly imperfect. At the end of the day, you’re running Netflix and Spotify on the same computer, and they still share a lot of resources. For example, they both use the same network card to fetch data from the Netflix and Spotify servers. They use the same graphics card to display data on your screen. They use the same processor to run their application code. And so on and so forth.
Consider why this type of resource sharing, however limited, might compromise security. Let’s say your roommate recently admitted to you that they’ve watched 20 movies in the last week. They know they’re addicted and need to focus on their work, but they can’t stop watching movies, and they need your help. To hold them accountable, it’s now up to you to figure out when they’re watching a movie, so you can go knock on their door and tell them to stop. There are two important facts that will help you solve this problem:
- Movies are very large files. Streaming one typically creates a lot of network activity.
- You both share the same Wi-Fi router.
One solution might involve periodically downloading a large file and measuring how long each download takes. If you notice that a download takes longer than usual, and this pattern holds for some period of time, you might begin to suspect that something is up. Why is the download taking longer? Have you ever asked a relative to stop watching a movie because you needed to take an important call on the same Wi-Fi network, or turned off video on your Zoom call so that the audio would cut out less often? Your Wi-Fi router can only handle so much activity at once, and since you and your roommate are sharing the same router, your network activity is impacted by theirs. You should go tell your roommate to stop watching their 21st movie of the week.
In this way, your Wi-Fi router creates a side channel, because it essentially reveals information about its users by accident. This side channel is extremely crude, only able to transmit one bit of information at a time (1 = roommate is watching movie, 0 = roommate is not watching movie), but it still illustrates a very important concept: nearly every shared resource reveals information about its users by accident. And when it comes to modern computers, there are lots of shared resources, which create lots of side channels.
Some notable examples of side channels that we learned about in Mengjia’s class blew my mind. For example, it’s been known for some time that changes in a computer’s power consumption can be used as a side channel. In the figure below, you can see a device’s power consumption, shown in yellow, reliably increasing and decreasing during RSA encryption, enabling you to identify the 1s and 0s that make up a user’s encryption key. An entire book was written about this type of attack over 15 years ago!
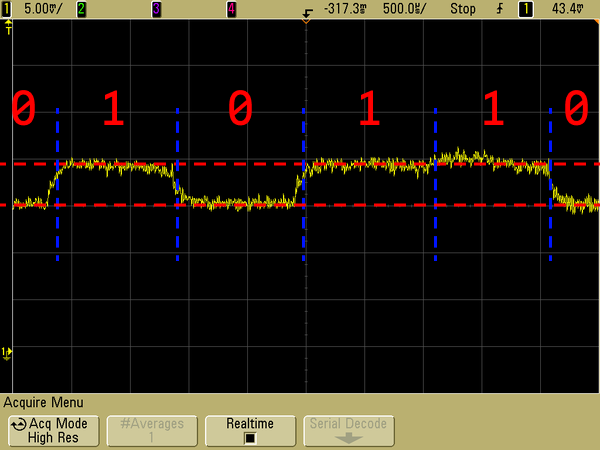
Similarly, every device, from your laptop to your contactless credit card, emits electromagnetic radiation, since any wire carrying a current creates a small magnetic field (remember the right-hand rule?). In a similar way to the power-analysis attack described above, you can monitor changes in this EM signal to reverse-engineer encryption keys, user activity, and more. I could go on and on. In most cases, though, these types of attacks are impractical to pull off—you need specialized equipment to monitor electromagnetic signals, and it’s hard to look at this signal and tell if someone is encrypting a message or just watching cat videos on YouTube. However, some side-channel attacks are much easier to pull off. Let’s get back to the topic at hand.
What is website fingerprinting?
Now, imagine you have two tabs open in your web browser. One is a big social media platform that wants to collect as much data about you as possible in order to serve better targeted advertisements. I don’t want to name an actual social media platform, so I’ll just make one up: let’s call it Facebook.2 In the other tab, you have a website open that you’d prefer “Facebook” didn’t know about—maybe it reveals something about your identity (e.g. Truth Social) or something you’d otherwise be ashamed for other people to know about (e.g. Taylor Swift fan page). How could Facebook figure out what website you have open in this other tab?
Facebook could turn to website fingerprinting to solve this problem. When Mengjia and I discussed my final project, she pointed me to a paper by Shusterman et al. that explores this exact setup, where one website attempts to identify the website open in another tab out of a set of 100 possible websites. They claimed to do this by taking advantage of a widely-studied side channel: the CPU cache. Their idea worked as follows: while your computer loads a website (or does anything, for that matter), it saves lots of data in small CPU caches in order to reduce the number of times it needs to load data from RAM or from your hard drive, both of which are much slower.

However, caches, like your Wi-Fi router, are shared resources, and they are generally very small. If RAM is a library that holds hundreds of thousands of books, the CPU cache might be a single bookshelf by the front door with a few of the most popular titles. When someone requests a book, if it’s on that bookshelf, they will get their book almost instantly. If not, they can go look for it in the library, but it will take much longer. The problem here is that your bookshelf will inevitably fill up, because it holds a fraction of the contents of the library. If you have two programs running on your computer, they will need to share the same CPU cache, which is also being used by your operating system and whatever other applications you have open at the time.
Now if you think about it, when you open any website, perhaps you’ve opened jackcook.com, it will load in basically the same way every time. It will reference the same scripts, images, and stylesheets, and it will render the same content on the page. And in theory, this should translate to very similar cache activity each time the website loads. This is where website fingerprinting comes in. To try to take advantage of this CPU-cache side channel, Shusterman et al. designed an attacker that worked as follows:
- Allocate an array that’s the same size as the CPU cache3 and fill it with ones.
- While a website loads in another tab, every 2 milliseconds, measure how long it takes to loop over the array and access every element.4
- Repeat step 2 for 15 seconds.
By the end of this process, making one measurement every 2 milliseconds for 15 seconds, the attacker will have 7500 measurements in total. Now, let’s consider for a moment why an individual measurement might be higher or lower, and remember that you’re opening another website while this happens, the one you don’t want “Facebook” to know about.
Facebook, which I will now refer to as the attacker, and the other website you’re loading, which I will now refer to as the victim, share a lot of resources on your computer.
One of these shared resources is the CPU cache: using the analogy from earlier, imagine the attacker and victim each have their own libraries with their own data, but they have to share space on the same small bookshelf to cache this data.
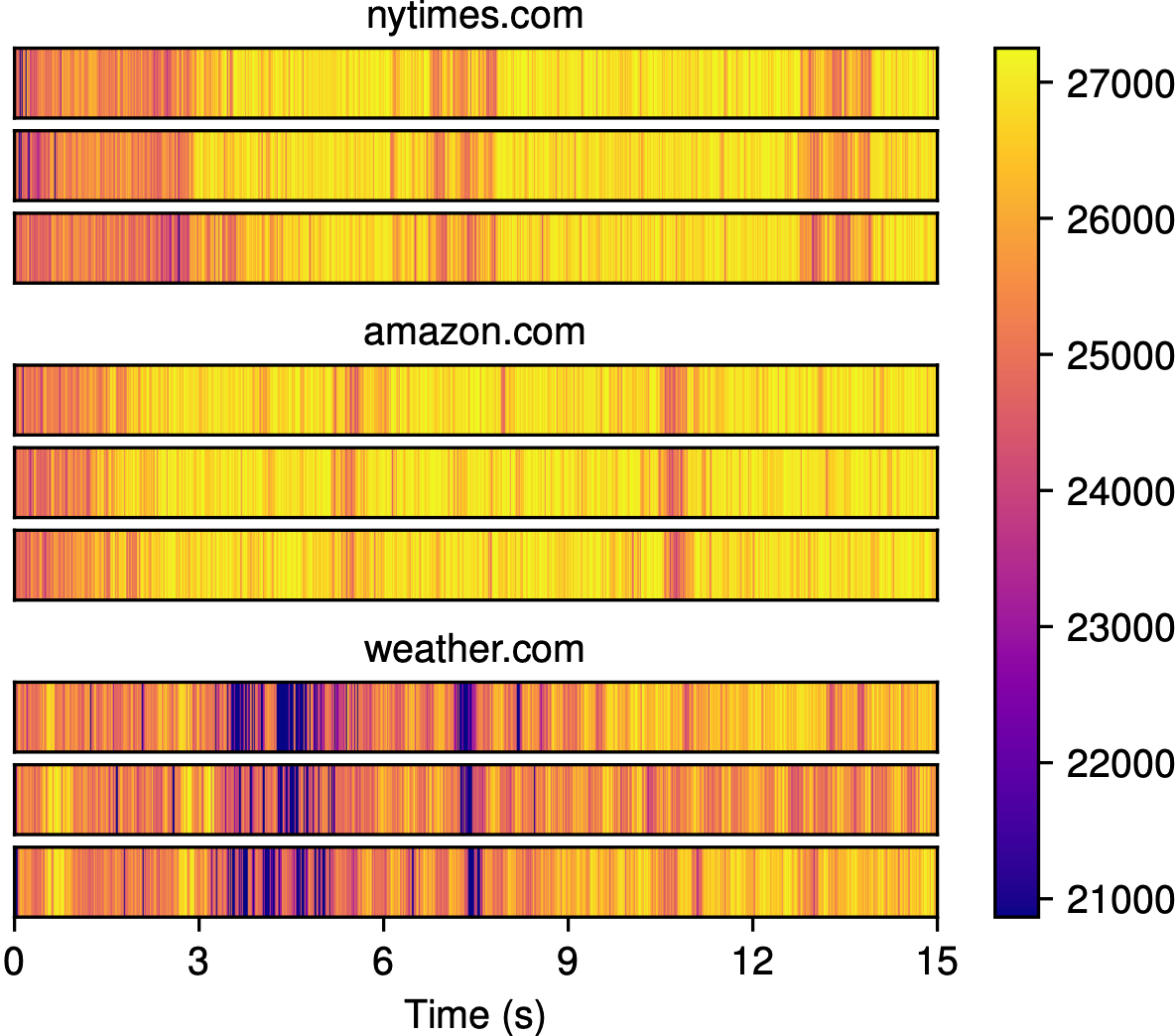
But then, 2 milliseconds later, the attacker will read all of its data again, and the CPU will first look for this data in the cache. If any of the attacker’s data was removed from the cache in the last 2 milliseconds, it will take a tiny bit longer to do this, because the CPU will need to spend time looking for it in RAM. And because the attacker is timing how long this process takes, it will notice this tiny discrepancy. This process will then repeat itself 7,500 times over the course of the next 15 seconds. And since websites generally load in the same way every time, these measurements should reflect the unique cache access patterns of the website you’ve opened. In the figure below, you can see how these measurements look for three different websites, where time increases to the right, and darker colors indicate slower cache accesses.
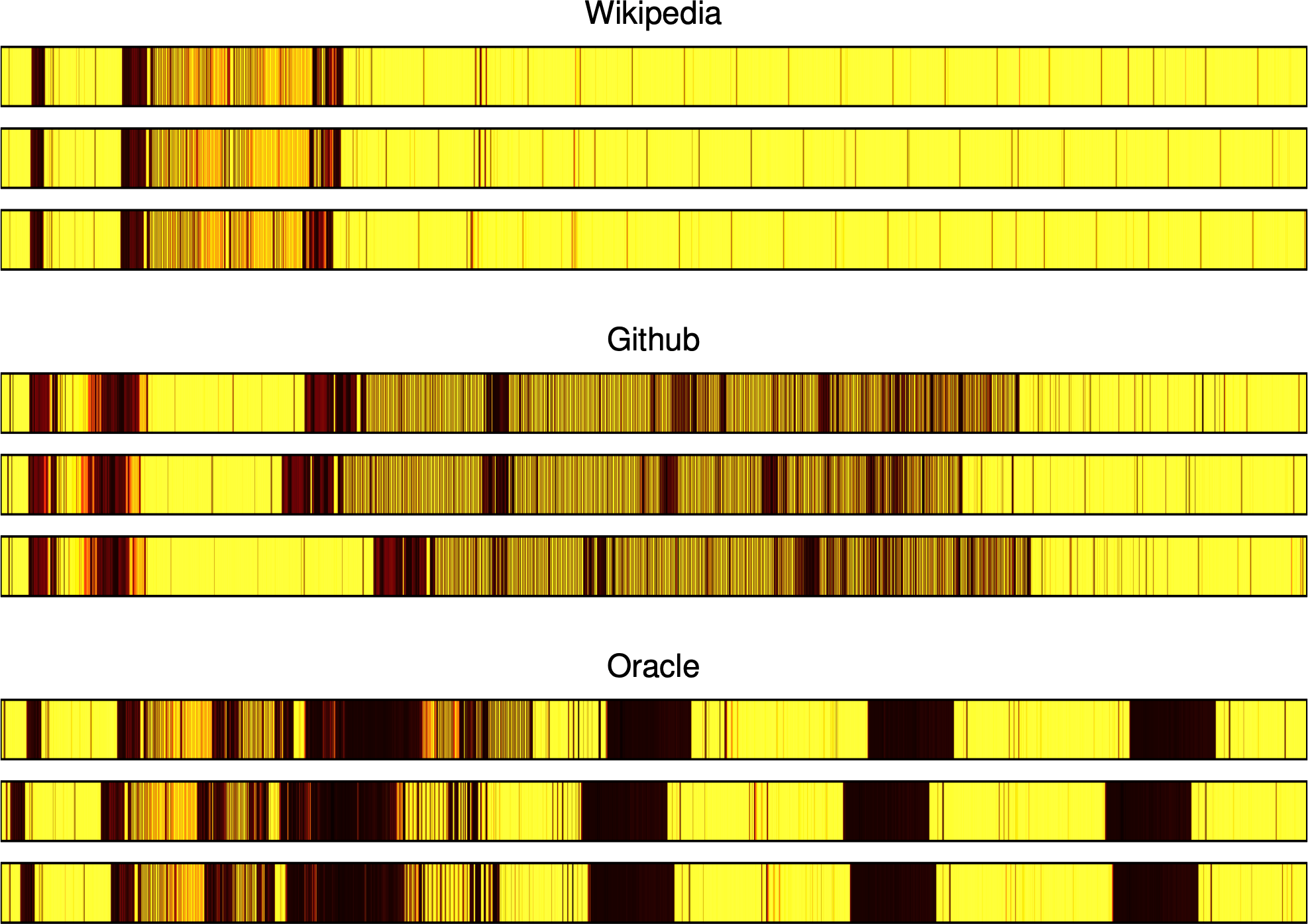
Notice how within each website, the traces look very similar, but across different websites, the traces look very different. This is where website fingerprinting gets its name: each collection of latency measurements, which we call a trace, essentially acts as a “fingerprint” that can be used to identify the website that was loaded. If I gave you a new trace from one of these websites and asked you to tell me which one it came from, you could probably compare it to the traces above and give me the answer.
Click the start button below to see this process in action by recording
Now, let’s go back to the example from earlier. Imagine you’re “Facebook,” and you want to identify the websites your users are opening in their other tabs. How would you do this? First, you might collect a bunch of traces while opening a lot of different websites, similar to the ones above, which you can use as training data. With this training data, you can train a machine learning model, which can reliably predict the website that was opened while recording one of these traces. Then, when users open “Facebook” in the future, “Facebook” can record new traces, feed them into this model, and see if there’s a match.
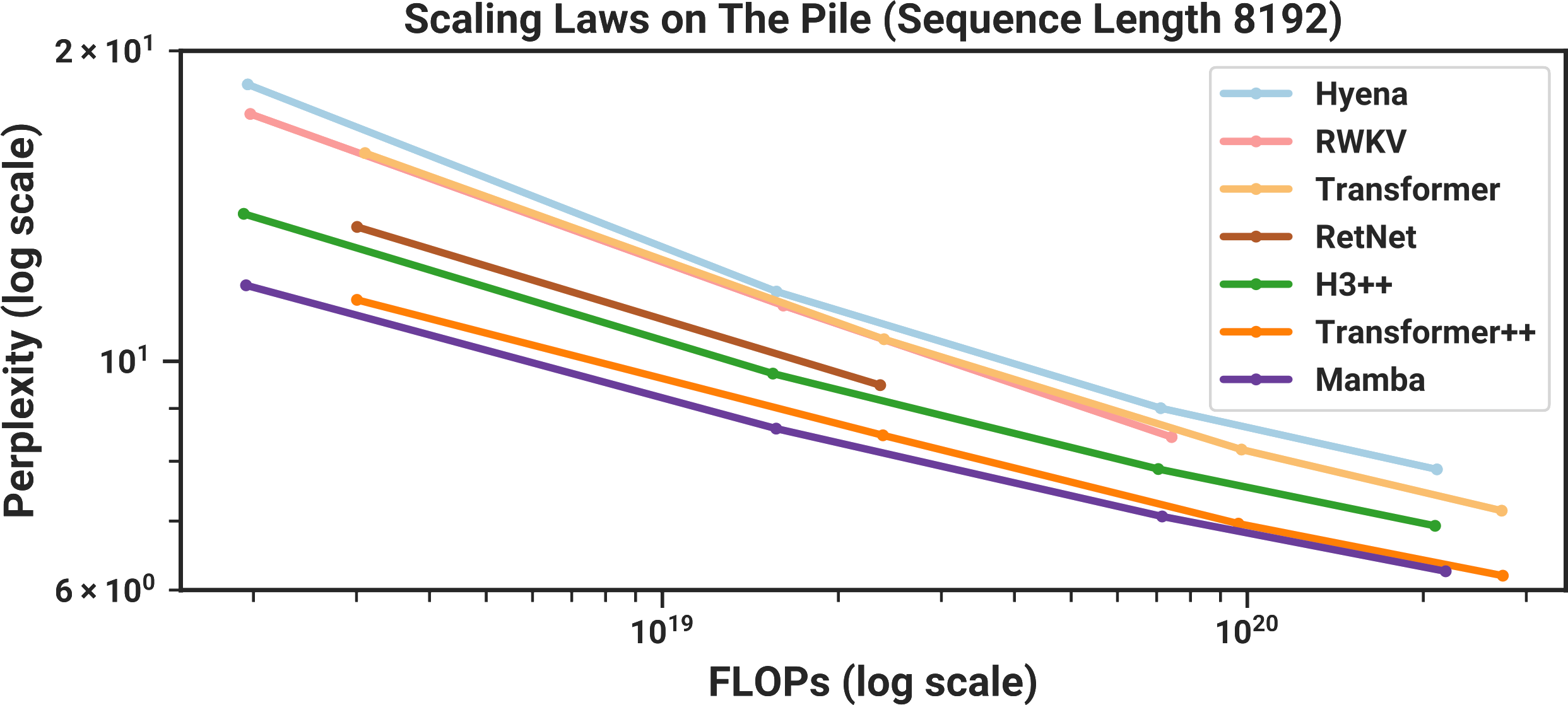
This is what Shusterman et al. did: in their paper, they collected 100 traces for 100 different websites, yielding a labeled dataset of 10,000 traces, and used it to train a few machine learning models. They then repeated this process across several different web browsers and operating systems, and found that it was possible to identify the website that was opened out of a set of 100 possible websites with up to 91.4% accuracy.6 Pretty cool, and a little scary!
| Web Browser | Operating System | Classification Accuracy |
|---|---|---|
| Chrome | Linux | 91.4% ± 1.2% |
| Chrome | Windows | 80.0% ± 1.6% |
| Firefox | Linux | 80.0% ± 0.6% |
| Firefox | Windows | 87.7% ± 0.8% |
| Safari | macOS | 72.6% ± 1.3% |
| Tor Browser | Linux | 46.7% ± 4.1% |
My final project
I spent the next few weeks trying to replicate these results from Shusterman et al.’s paper. Going into this project, I wasn’t too sure what I would find. Mengjia and I decided I should look at website fingerprinting because I had past experience with web development and machine learning, and not because there was an obvious unresolved research question. I collected a bunch of data and tried to distinguish between four websites at a time, which was fairly straightforward.
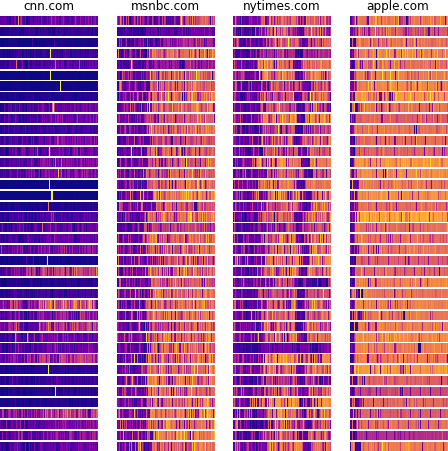
Even if you just looked at these traces with your own eyes, there are clear patterns that distinguish these websites from each other. If I gave you a new trace, you could probably tell me which website it came from. But of course, models do this faster and more reliably. By training a simple Random Forest classifier on these traces, I was able to predict the correct website with 98% accuracy. Scaling this up to 10 websites initially gave me 75% accuracy, but over the next several weeks, I kept experimenting and making improvements until I could reliably classify 10 websites, then 50, then 100.
While many of these experiments led to small improvements, one stood out above the rest.
Remember that in Shusterman et al.’s paper, the attacker works by repeatedly measuring how long it takes to access all of the elements in its array.
For one of my experiments, I tried a different approach: I simply made the attacker count as fast as it could (like literally, execute value++ over and over again).
In the demo below, click Start and hover over or tap on the final trace to see how high your computer can count in 5 seconds.
Of course, this number doesn’t tell us too much on its own. However, if we do this repeatedly, we can see how fast your computer can count over time. Now see how high your computer can count in one second, five times in a row.
As we make this interval smaller, we can see how this plays out at a finer timescale. Again, hover over or tap on the values in these traces to see what each measurement represents.
Now, play with the demo above to see if you can get the trace to change. If you do nothing, the values should stay relatively consistent over time. But if you click start and then do something else on your device, such as opening a new tab or resizing the browser window, you should see this reflected in the trace. If you’re having trouble with this, you can see an example below:
Take a second to think about what’s happening here. In the video above, over the course of 5 seconds, my computer tried to count as fast as it could. Every 100 milliseconds, we saved the value it reached, and made it start over again from zero. As was the case with the cache-based attacker, this trace is sensitive to things that happen outside of the same browser tab: when I opened Google Maps, my computer couldn’t count as high.
This shows that this counter trace can essentially be interpreted as a signal. We can improve the resolution of this signal by saving the value more often: while I saved the value every 100 milliseconds in my demo to illustrate the concept of our counting-based attack, in our paper, we save the value every 5 milliseconds to get more information in a fixed amount of time. In the demo above, you can change this value, which we call the period length, to record counter traces at a higher or lower resolution. A simple version of the trace collection code is shown here in Python, which you can read or try for yourself:
import time
PERIOD_LENGTH = 0.1 # 0.1 second
TRACE_LENGTH = 5 # 5 seconds
start = time.time()
counter = 0
trace = []
while len(trace) < int(TRACE_LENGTH / PERIOD_LENGTH):
if time.time() - start >= PERIOD_LENGTH:
trace.append(counter)
start = time.time()
counter = 0
continue
counter += 1
print(trace)I ran the experiment, training a model on these counter traces rather than using the cache-latency traces we discussed earlier. And as it turned out, models trained on the counter traces were more accurate at predicting the website that was opened!
This was a really exciting result! The theory behind Shusterman et al.’s paper was that their attacker leveraged a CPU-cache-based side channel by repeatedly evicting data from the cache and measuring cache access latency. But my new attacker simply incremented a counter, without needing to repeatedly evict data from the cache, and it appeared to yield an even better signal. There was no solid theory behind it. Why did it work so well?
I presented my findings during the final lecture of Secure Hardware Design, and Mengjia was even more excited than I was. A few days after that lecture, she sent me the following email:
Hi Jack,
Great job on the 6.888 course project! As I have commented during the lecture, your work is really impressive.
I am wondering whether you will be interested in continuing the project in my group. My group offers [undergraduate research] opportunities. I am very curious about why your new measurement approach could do a better job than cache-contention attacks. By digging deep into it and figuring out the reason, we can potentially find something unknown to the public related to how the browser or hardware processor works, and get a potential publication in a top security or computer architecture conference.
If you are interested, we could chat about details after your finals and the holiday season.
Thanks, Mengjia
I didn’t realize it at the time, but I had accidentally discovered a new side channel.
Investigating the mystery side channel
I called Mengjia several weeks later, after the end of my 6-week roadtrip across the US, and joined her lab in February 2021. She introduced me to Jules Drean, a talented graduate student who studies micro-architectural side-channel attacks such as this one, and the three of us immediately got to work trying to understand why my new attacker worked so well. As it turned out, the picture was complicated, but one thing was clear: machine learning models need to be used carefully.
This would become the biggest lesson of our eventual research paper: in a machine-learning-assisted side-channel attack such as this one, if a model can reliably predict user activity, it proves the presence of a signal, but not the cause of that signal.7 Even though Shusterman et al.’s model could identify the correct victim website 91.4% of the time, that didn’t necessarily mean that their model was picking up on contention over the CPU cache. And the implications of getting this wrong can be big: researchers look at papers describing attacks when building defenses that make our computers safer. A more thorough analysis was needed in order to properly identify the side channel, which we set out to provide.
We started by replicating the larger experiments from Shusterman et al.’s paper to understand the similarities and differences between our counting-based attacker and their cache-based attacker. It turned out that when asked to identify the correct victim website out of 100, my counting-based attacker achieved higher accuracy in nearly every experimental configuration we tried.
| Web Browser | Operating System | Cache Attack | Counting Attack |
|---|---|---|---|
| Chrome | Linux | 91.4% ± 1.2% | 96.6% ± 0.8% |
| Chrome | Windows | 80.0% ± 1.6% | 92.5% ± 1.0% |
| Firefox | Linux | 80.0% ± 0.6% | 95.3% ± 0.7% |
| Firefox | Windows | 87.7% ± 0.8% | 91.9% ± 1.2% |
| Safari | macOS | 72.6% ± 1.3% | 96.6% ± 0.5% |
| Tor Browser | Linux | 46.7% ± 4.1% | 49.8% ± 4.2% |
For some configurations in particular, this discrepancy in performance was huge: in Safari on macOS, the cache attack achieved just 72.6% accuracy, while our counting attack achieved 96.6% accuracy on the same task. These results really seemed to suggest that the cache may have been interfering with our signal rather than helping it! But again, we couldn’t say this for sure without a more thorough analysis. So over the next several weeks we applied the scientific method, modifying one variable at a time, collecting new data, and training new models to eliminate different hypotheses about what was going on. First, we established a baseline, where we simply ran the attacker in its default configuration without any modifications, and found that we could identify the correct website out of 100 with 95.2% accuracy.
Hypothesis 1: CPU frequency scaling
We then tested our first hypothesis, which was that our counting-based attack was taking advantage of a CPU-frequency-scaling side channel.
CPUs operate at a set frequency, which reflects the amount of work they can do per second.
For example,
We hypothesized that while the victim website is loading, the CPU would change its frequency often, enabling it to complete variable amounts of work over time. And for our attacker, completing more work should enable it to count faster, yielding higher values at specific points in time while the other website loads, or vice versa. But it turned out this wasn’t the case: we went into BIOS, disabled frequency scaling, collected more data, and trained another model. Compared to the baseline experiment, our accuracy dropped by just one point to 94.2%, indicating that changes in counter values can’t really be explained by changes in CPU frequency. We started filling out a table to keep track of our results:
| Isolation Mechanism | Accuracy |
|---|---|
| Default | 95.2% |
| + Disable CPU frequency scaling | 94.2% |
Hypothesis 2: CPU core contention
Next, we thought our counting-based attack might have been exploiting a CPU-core-contention side channel.
Your
But this was also wrong.
With CPU frequency scaling still disabled, we ran an experiment with Linux’s taskset command, which can be used to force a process to execute on a specific CPU core, and ensured that the attacker and victim tabs ran on separate cores.
Even when the attacker and victim were isolated in this way, the attacker still seemed to have plenty of information: it could still pick the correct victim website out of 100 with 94.0% accuracy.
| Isolation Mechanism | Accuracy |
|---|---|
| Default | 95.2% |
| + Disable CPU frequency scaling | 94.2% |
| + Pin attacker and victim to separate cores | 94.0% |
At this point, we were a little stumped. CPU caches, frequency, and core resource contention are relatively well-studied side channels, and we had already ruled out all three of them. We sent out some emails and gave presentations within the department to see if anyone had ideas. Fortunately, Jonathan Behrens answered our call.
Hypothesis 3: System interrupts
After some further discussion, we hypothesized that our counting-based attacker might be exploiting a system-interrupt-based side channel. This idea was a bit out of left field: we couldn’t find any prior research that had studied the security properties of system interrupts. In hindsight, this is a little surprising considering how pervasive they are: your operating system uses system interrupts constantly to communicate with hardware devices, such as your keyboard, mouse, and display.
Compared to software, hardware is fairly unpredictable: anything can happen at any moment.
For example, your operating system has no idea when you’re next going to hit a key on your keyboard.
But once you do, your operating system needs to act as quickly as possible.
It generates a system interrupt, which it dispatches to one of your
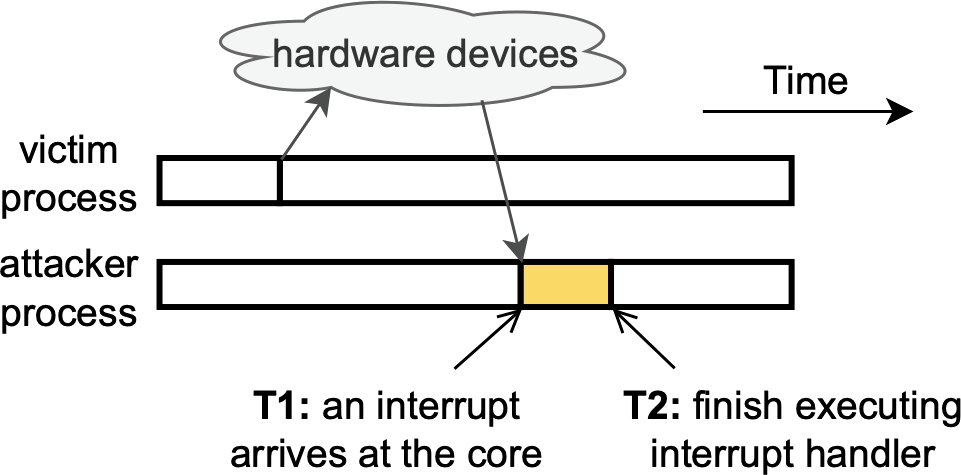
We thought that while the victim tab was loading, it would trigger many different kinds of interrupts: from your network card as it uploads and downloads data, from your graphics card as it renders content on your screen, and so on and so forth. If any of these interrupts is processed on the same CPU core as the attacker program, your operating system would need to halt the attacker each time, preventing it from counting until each interrupt handler (shown above in yellow) has finished processing. And remember, in the demo from earlier, we learned that less time spent counting leads to lower counter values, which can be highly indicative of activity happening elsewhere on your computer.
It turns out that on Linux, where we were running these experiments, you can monitor system interrupts very easily.
For example, if you run cat /proc/interrupts on Ubuntu, you should get a readout that resembles the table below:
| ID | Interrupt Type | Core 1 | Core 2 | Core 3 | Core 4 |
|---|---|---|---|---|---|
16 |
usb1 (Mouse) |
31 | 0 | 0 | 0 |
23 |
usb2 (Keyboard) |
1943 | 934 | 0 | 0 |
27 |
enp2s0 (Network card) |
0 | 376 | 0 | 10880 |
28 |
ahci (SATA/hard drive) |
8201 | 0 | 11531 | 0 |
30 |
i915 (Graphics card) |
0 | 193 | 0 | 364 |
NMI |
Local timer interrupts | 22059 | 18076 | 19010 | 27837 |
IWI |
IRQ work interrupts | 5794 | 4910 | 4950 | 7493 |
RES |
Rescheduling interrupts | 1400 | 1339 | 1359 | 1262 |
CAL |
Function call interrupts | 6122 | 6547 | 6563 | 3100 |
TLB |
TLB shootdowns | 295 | 377 | 285 | 290 |
This table shows that many interrupts are being processed on all four cores, very likely interfering with the attacker’s counting! So naturally, the next experiment we would like to run should isolate the attacker from these interrupts, letting the attacker count freely on one core while interrupts are processed on another core. But after doing some research, we came across a problem.
Linux provides a mechanism to route certain types of interrupts, which we call movable interrupts, to a specific core. These interrupts have numeric IDs in the table above, and generally come from external hardware devices, such as your keyboard and network card. However, there are also many types of non-movable interrupts which can’t be routed to a specific core, meaning we can’t isolate them from the attacker. These interrupts have three-letter IDs in the table above, and are generally used to synchronize activity between your CPU cores, which is why modern operating systems require that they be processed on all of them. And unfortunately for us, as you can see in the table above, these non-movable interrupts make up the bulk of interrupt activity.
But we didn’t let this deter us.
We used Linux’s irqbalance command, which can be used to force certain interrupts to be processed on a specific CPU core, and routed all movable interrupts to core 1.
Building on the previous experiments, we additionally used taskset to force the attacker and victim to run on cores 2 and 3, while also forcing the CPU to run at a fixed frequency as we described earlier.
Even though we could only isolate movable interrupts, it seemed like we were onto something: the attacker’s accuracy dropped by nearly six points!
| Isolation Mechanism | Accuracy |
|---|---|
| Default | 95.2% |
| + Disable CPU frequency scaling | 94.2% |
| + Pin attacker and victim to separate cores | 94.0% |
| + Isolate movable interrupts | 88.2% |
Hypothesis 3.5: Non-movable system interrupts
Of course, this result left us wondering what the attacker’s accuracy would be if we could isolate non-movable interrupts as well. But again, this type of experiment is impossible: due to fundamental limitations of how operating systems are built, non-movable interrupts must be processed on every core. If we wanted to understand the impact of these interrupts, we had to use a different approach.
This was where Jonathan’s expertise proved crucial: he suggested we use eBPF, a low-level technology that can be used to make small changes to your operating system while it’s still running. Among the many APIs it provides, eBPF enabled us to record two crucial things:
- Every time the attacker program starts and stops
- Every time an interrupt handler starts and stops
Remember, CPU frequency scaling is still disabled, meaning that the CPU executes a fixed number of instructions per second. In theory, this means that if the attacker is uninterrupted, it should always be able to reach the same counter value in a fixed amount of time. We figured that if we could record every time interval during which the attacker was interrupted, whether to run another program, to process an interrupt, or for some other unknown reason, we could compare this to every interval during which an interrupt was processed, and see if these explained the gaps in the attacker’s execution.
Jonathan wrote the code to do this with eBPF, recording hundreds of these timestamps while our attacker counted away. If we go back to the figure from earlier, we measured all of these yellow regions, during which the attacker was interrupted:
We analyzed these gaps in the attacker’s execution, hoping to get an understanding of what was going on, and it turned out that our intuition was right. Out of all of these gaps that last at least 100 nanoseconds, we found that over 99% of them are spent processing interrupts! This was the smoking gun we had been looking for all along!
Essentially, during our experiments, the attacker’s CPU core is basically only ever doing one of two things: processing the attacker’s counting code, or processing an interrupt. And since the CPU is running at a fixed speed, the amount of time spent processing the attacker’s code should be proportional to the number of times it’s able to increment its counter. In the figure below, you can see this for yourself: while loading a victim website, the attacker’s counter value generally goes up when less time is spent processing interrupts, and vice versa.
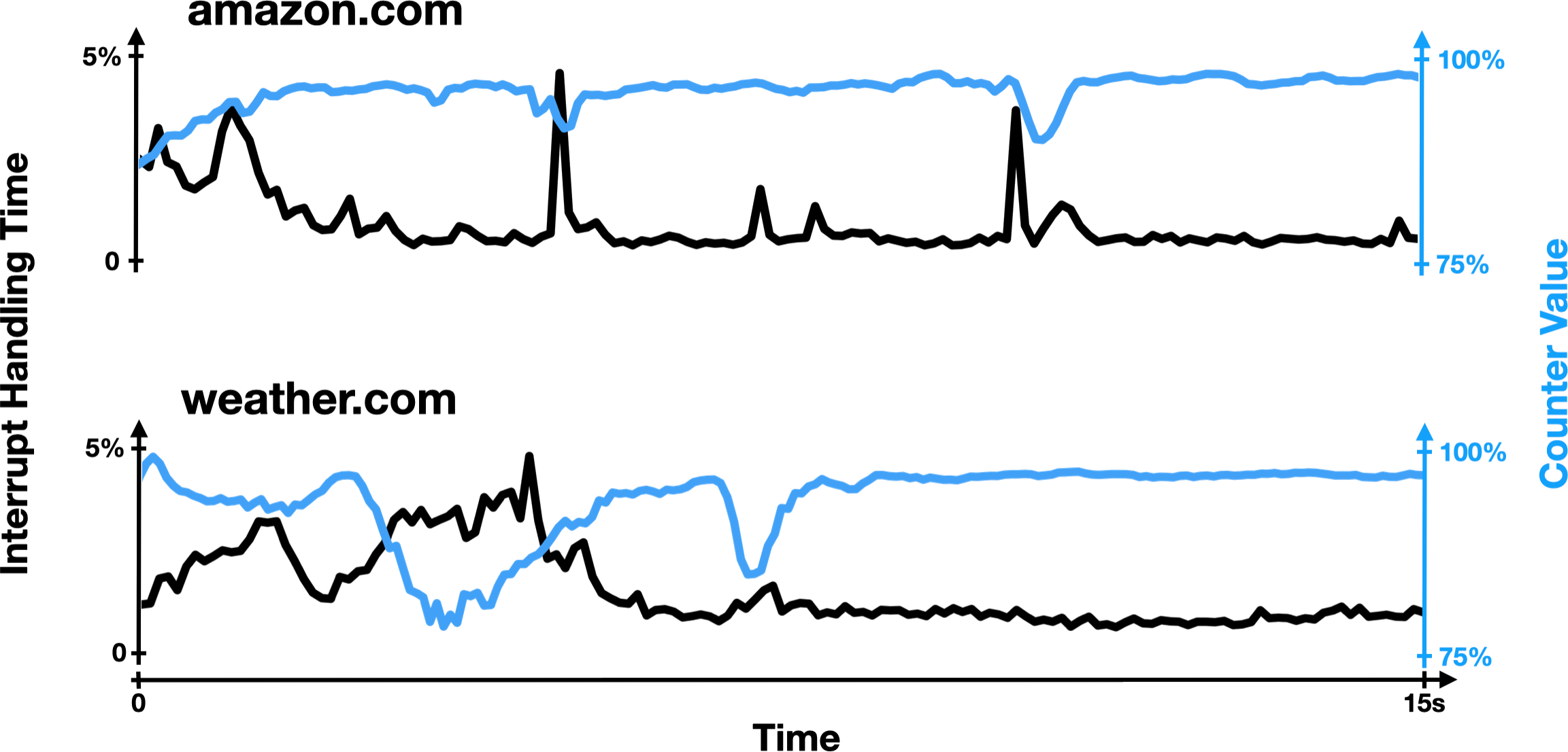
Now that you understand what’s going on, I encourage you to try this demo again, seeing what happens if you do something in the middle of trace collection that triggers a bunch of interrupts. Some suggestions include opening a new tab, pressing a bunch of buttons on your keyboard, moving your mouse around really quickly, or opening an application.
You can also try our online demo here, or check out our trace collection code on GitHub!
There’s always a bigger fish
That was a lot! My apologies if I lost you in some of the technical details. Let me take a step back and summarize what we did one more time:
- We re-implemented a state-of-the-art cache-based website fingerprinting attack
- We modified it to remove cache accesses, yielding a new counting-based attacker which took advantage of some unknown side channel
- We ruled out several possible side channels, including CPU caches, CPU frequency, and CPU core contention
- We used eBPF to prove that this attack primarily leverages a system-interrupt-based side channel
And through this process, we came away with two key findings:
1. System interrupts leak user activity
This was a fairly surprising finding: the security properties of system interrupts had never been demonstrated before. We became the first group to study this new system-interrupt-based side channel, and we likely won’t be the last: there are tons of directions for future work! I’ll come back to this in a moment.
2. Machine-learning-assisted side-channel attacks need to be analyzed carefully
This is arguably our most important takeaway, and almost certainly the reason we ended up winning those awards from Intel and IEEE. Machine learning models are great at finding patterns in data and can be used regardless of one’s understanding of the side channel being attacked, which leads to the development of powerful attacks that are poorly understood.
Without instrumenting our operating system, we could not have made many conclusions about which side channel our attack was exploiting: it’s impossible to do this with models that can only find correlations! And it’s important to get this right—an incorrect analysis of an attack can mislead researchers hoping to build defenses, wasting valuable time and energy.
For example, in their paper, Shusterman et al. proposed a defense against their attack that involves repeatedly evicting data from the CPU cache while the attacker tries to collect data. The idea was driven by their understanding of the side channel being exploited: adding noise to the CPU cache should make it more difficult to exploit a cache-based side channel. However, we found that a defense that instead generates a bunch of interrupts, such as by making network requests to local IP addresses, defends significantly better against both the cache-based attack and our counting-based attack!
| Attack | Baseline | With Cache Noise | With Interrupt Noise |
|---|---|---|---|
| Counting Attack (ours) | 95.7% | 92.6% | 62.0% |
| Cache Attack (Shusterman et al.) | 78.4% | 76.2% | 55.3% |
This is a relatively simple example, but it shows how having a better understanding of the side channel being exploited can increase our ability to defend against it. In combination with our other findings, it also helped us build our case that Shusterman et al.’s attack primarily exploits signals from interrupts, and not the cache. We hope this work motivates future researchers to apply these models carefully.

Other findings
There are a few more interesting findings in our paper if you’re curious to keep reading! A couple of these include:
- We proposed a modification to the clock provided to JavaScript code that completely mitigates our attack
- We ran experiments that isolated the attacker and victim by putting them in separate virtual machines, which should theoretically offer the most isolation possible
- We discussed and analyzed the properties of several types of non-movable interrupts, including how frequently some of them fire and exactly how long they take to process
And more! Unfortunately this blogpost is already long enough as it is.
Future work
There are a bunch of open questions in this area, even today, two years after we originally published this paper. Here are a few that are still at the top of my mind. If you find any of these interesting, please get in touch!
How should we rethink interrupts?
Similarly to Spectre and Meltdown, our attack targets hardware mechanisms that are embedded deep inside basically all modern computers. It’s currently impossible to implement a defense that isolates non-movable interrupts from an attacker, and it’s unclear how computers would be redesigned in a way that makes that possible. Figuring this out presents an important direction for future research, especially if attacks such as ours become more accurate in the future.
The relationship between websites and interrupts is not well understood
Below, you can see a figure from our paper, in which we show how interrupt handling time varies while loading three different websites. Notice that the behavior, and even the types of interrupts, are different: loading weather.com triggers a lot of rescheduling interrupts, but nytimes.com and amazon.com don’t trigger any!
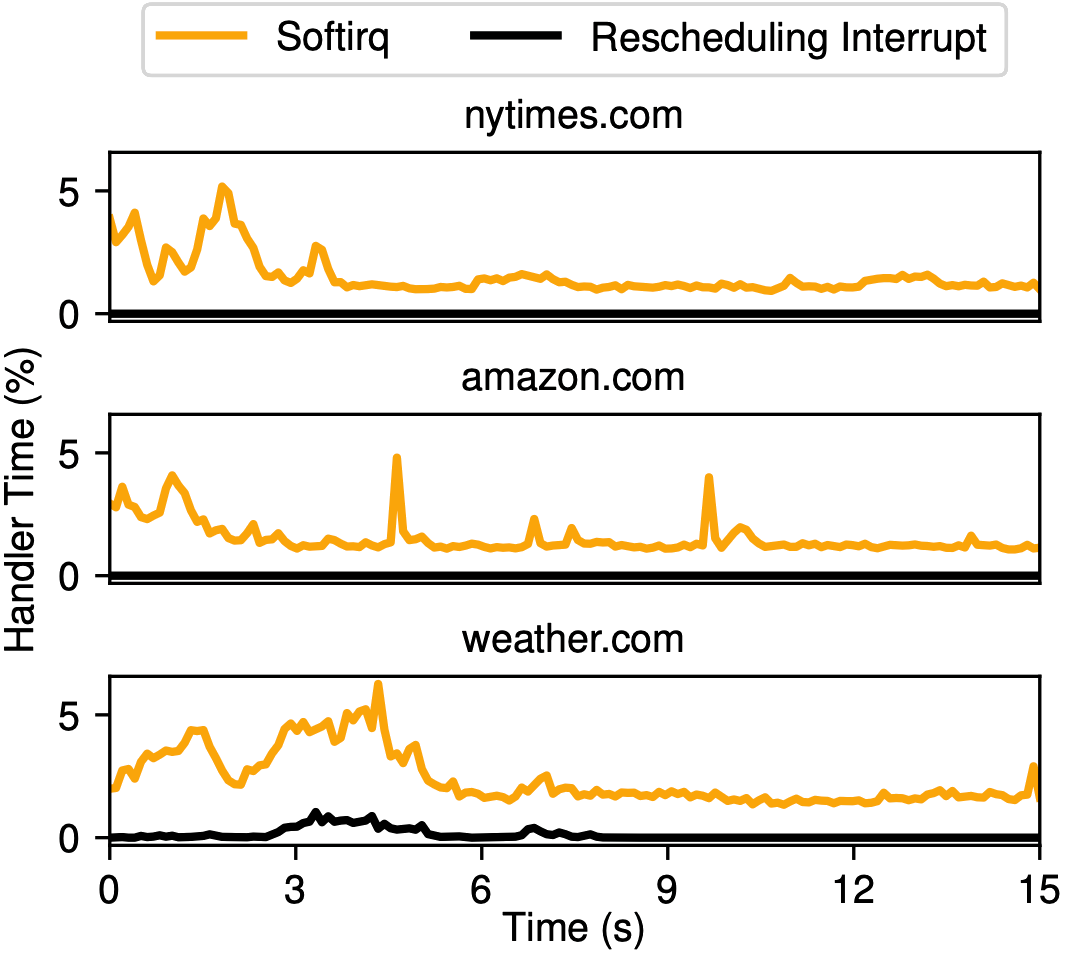
We don’t know why this is: clearly, there is something that weather.com is doing, perhaps loading more video content or more scripts or something, that the other two websites are not. At a more basic level, we’re not really sure what the relationship is between website activity and triggered interrupts. What impact does loading one additional image have on the attacker’s counter trace? What about an advertisement? What is it exactly that makes the counter traces so distinctive that we can tell them apart so easily? We didn’t spend time trying to answer these questions, but a better understanding of this relationship would likely help us build better defenses against system-interrupt-based side-channel attacks such as ours.
The attack could be made stronger
We wrote this paper as more of an “analysis paper,” and not as an “attack paper.” In theory, the 96.6% accuracy that we achieved when identifying the victim website in Chrome on Linux is a lower bound, not an upper bound. It’s pretty likely that a better model, or a different methodology, could achieve higher accuracy. And if it’s possible to achieve higher accuracy on this 100-website task, it’s likely possible to perform well on a 1,000-website task, or on some other privacy-compromising task: figuring out what movie you’re watching, or whether you’re using a VPN, or how often you check Robinhood.
Browser-based defenses could be made stronger
All browsers reduce the precision of the clock that they provide to websites via JavaScript: instead of telling you it’s 10:33:13.726142 (13.726142 seconds after the clock strikes 10:33am), your browser might just round to the nearest millisecond and tell you it’s 10:33:13.726. This is because with access to higher-precision timers, attacks such as ours become much more accurate (see Oren et al., 2015).
As a result, Chrome rounds its clock to the nearest 0.1 millisecond and adds some random noise, while Firefox and Safari round to the nearest 1 millisecond. Tor Browser, the world’s most popular secure web browser, rounds to the nearest 100 milliseconds, reducing our attack’s accuracy from 96.6% (in Chrome) to 49.8%. There is a tradeoff here: browser-based game engines, for example, need a high-precision timer in order to render and animate content correctly. As a result, Tor Browser users are unable to play most games, but this is not necessarily a problem for users who care about security.
In Section 6.1 of our paper, we propose a slight modification to browser clocks that completely mitigates our attack. I think it’s a step in the right direction, but more work needs to be done to implement this defense into real web browsers, and to examine whether it’s practical for most users.
How this paper changed my life
Before taking Mengjia’s class, the thought of going to graduate school had crossed my mind, but it was not an option I was taking seriously. One year prior, I had worked at NVIDIA as a deep learning research intern, and I loved it. After graduating, I probably would have looked for a full-time job there, or at another big tech company, or at some AI startup.
But this project showed me that research can be fun, and maybe even beautiful. It was a result of myself and three talented researchers coming together, each with a different background and skillset, to learn and create new knowledge together. This realization changed my life: after graduating from MIT with this paper under my belt, I stuck around for another year to earn my MEng in computer science, which I would not have done if not for this project. I then applied for a Rhodes scholarship, which I absolutely would not have won had it not been for this project, and which enabled me to spend two years studying at the University of Oxford. Next year, I will start my six-year PhD in computer science back at MIT, and I could not be more thrilled!
I am grateful to Jules, Jonathan, and especially Mengjia, for making this project possible, and for taking a chance on me—I can only hope that my future research projects will be as exciting and formative as this one.































{kind=link}